帕累托分析中的累计优化
帕累托分析又称ABC分析,也许有些人是第一次听到这样的叫法,实际它就在我们的身边。比如世界上百分之九十的财富掌握在十个人手里;头部商品占了公司80%的营业额;项目中应该把80%的时间投入到那80%重要的20%的事情中去。
回到主题,今天,要介绍的是在实际业务中计算ABC分类时累计值应该怎么算。为了方便看出效果,模拟数据比较简单
为了方便调整ABC的分类的阈值,这里也创建了一个参数
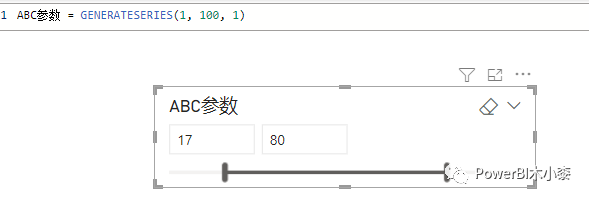
对应的A的值和B的值如下:
A范围 = MIN( 'ABC参数'[ABC参数] ) * 0.01
B范围 = MAX( 'ABC参数'[ABC参数] ) * 0.01
基础度量如下
销售 = SUM('销售表'[销售])常规ABC
我们最常见的计算累计的思路也很简单,销售大于等于当前产品销售的所有产品的累计销售额
累计销售 =
VAR cursales=[销售]
RETURN
CALCULATE (
[销售],
FILTER (
ALL ('销售表'),
'销售表'[销售] >= cursales
)
)计算累计占比就更简单了,累计销售除以所有产品的销售额就可以了。
累计占比 =
DIVIDE ( [累计销售], CALCULATE ( [销售], ALL ( '销售表' ) ) )这样其实会造成一个问题,如果有销售额相同的产品,那么在计算他们的累计收入时,其实是多算的,这样它的累计占比也会多算。比如下图中商品4和商品5,其实在计算累计销售额时是240+30+30=300,按照我们常规的思路,应该是逐行累计,即商品4的累计销售应该是240+30=270,商品5的累计销售应该是270+30=300。
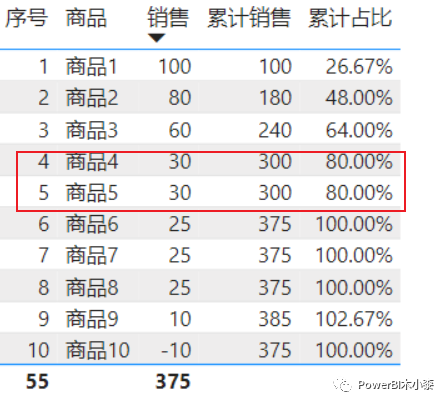
我们先继续看ABC分类的值,上面已经算出来了每个商品的累计占比,只要用累计占比和A、B的界限值比较就可以了。
ABC分类 =
VAR cur = [累计占比]
RETURN
SWITCH (
TRUE (),
cur <= [A范围], "A",
cur <= [B范围], "B",
"C"
) 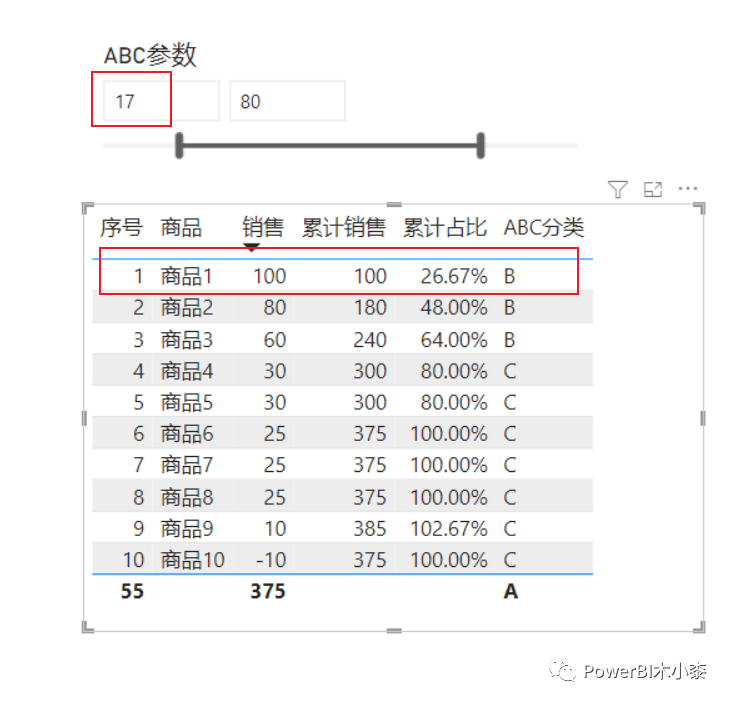
看到这个结果,至少我是要为商品1打抱不平的,明明它自己就占了总体的26%了,只是因为它超过了A的阈值就把它分到了第二档的B里去。
我们还可以为不同类别分配不同的颜色
ABC配色 =
VAR cur = [累计占比]
SWITCH(TRUE(),
cur<=[A范围],"#0e7388",
cur<=[B范围],"#43BF94",
"#99E080"
)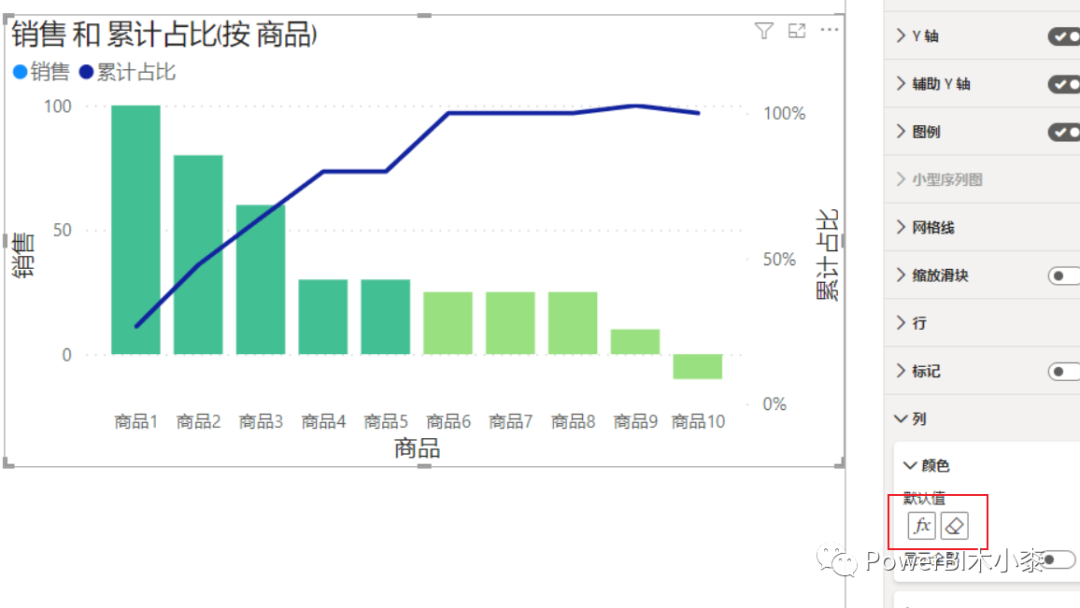
这里其实还有个问题,就是累计占比的曲线并不是平滑向上的,这其实是我上面提到的算累计值的问题属于同一个。
逐行累计
我们先来解决上面提到的第一个问题,就是算累计的时候逐行累计,其实逐行累计也能解决在图表上看累计占比的时候是条相对平滑的曲线的问题。
这里我们先用变量获取当前商品的序号,这样就可以像在Excel中那样逐行累加了,每次计算累计值时只计算小于等于当前序号的,
累计销售2 =
VAR cursales = [销售]
VAR curindex =
SELECTEDVALUE ( '销售表'[序号] )
RETURN
CALCULATE (
[销售],
FILTER (
ALL ( '销售表' ),
'销售表'[销售] > cursales
|| AND ( '销售表'[销售] = cursales, '销售表'[序号] <= curindex )
)
)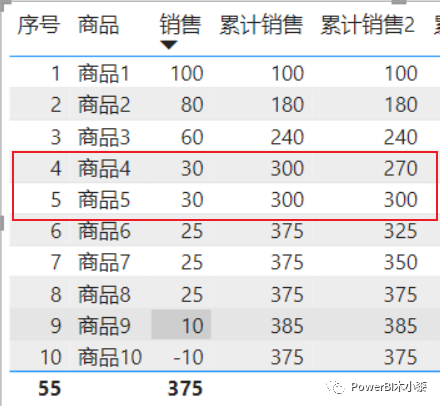
这里就可以看到在商品4时的累计销售是270,商品5的累计销售是300,是符合我们逐行累加的预期,只是它又带来了另一个问题,商品4和商品5的销售明明相同,只是商品4的序号在前面而已,商品4就是B类,而商品5就是C类。虽然现实世界可能是存在这样的事的,比如两个人考研的总分相同,可能录取就是笔试成绩高的那个。
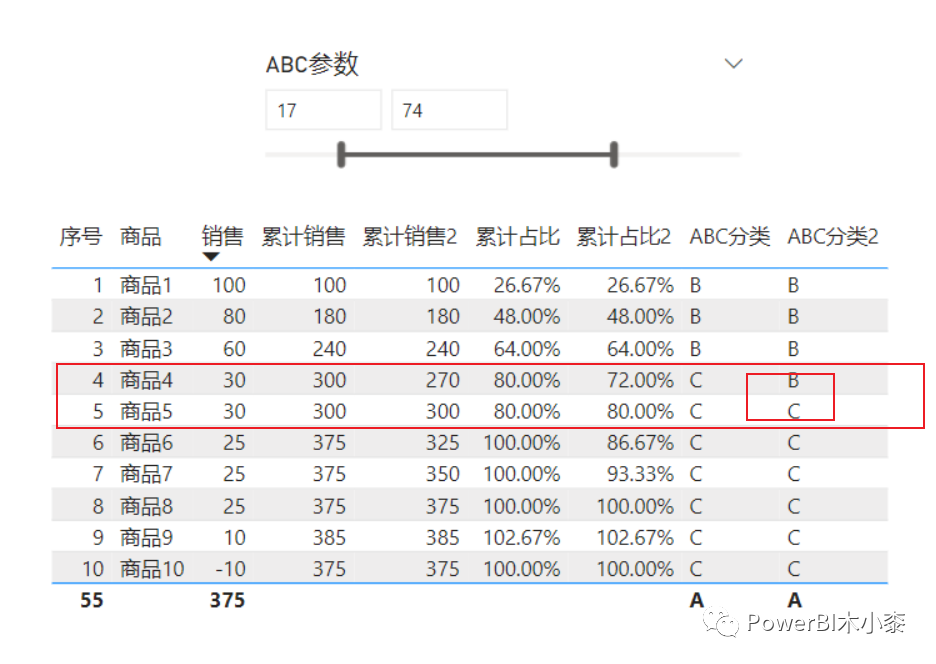
采用这种方法,累计占比不会出现相同的,所以曲线相对平滑
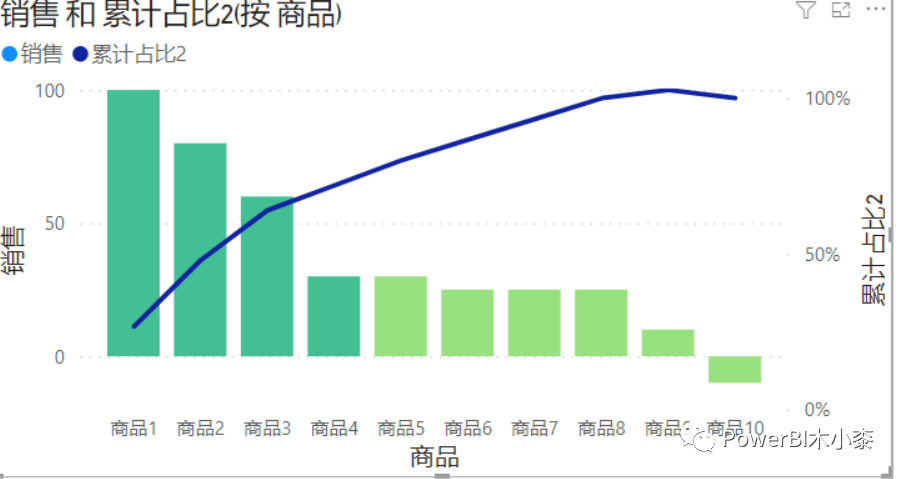
逐行累计优化
为了避免上面说到的商品4和商品5销售一样却分到不同类别的问题,我们继续来优化,在上述方法的基础上,这次如果遇到销售额相同的,不再累加比销售额和它相同但序号比它小的商品的销售额,即,无论和当前商品相同销售额的商品有几个,在计算当前商品的累计销售额时只计算一次。
累计销售4 =
VAR cursales = [销售]
VAR curindex =
SELECTEDVALUE ( '销售表'[序号] )
RETURN
CALCULATE (
[销售],
FILTER (
ALL ( '销售表' ),
'销售表'[销售] > cursales
|| AND ( '销售表'[销售] = cursales, '销售表'[序号] = curindex )
)
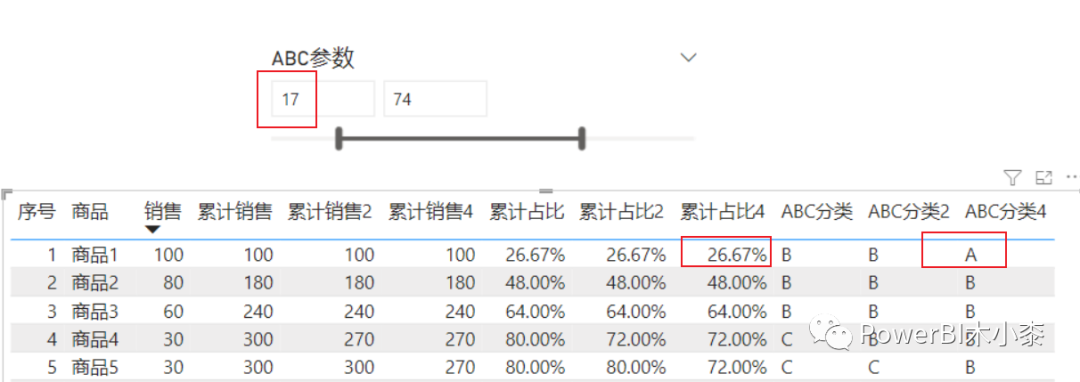
)其实,这种算法有点类似考试排名,第一名一个人,第二名三个人,然后就直接跳到第五名。所以图中商品4和商品5的累计占比都是72%。

接下来再解决另一个问题,就是商品1的分类问题,即只要最大销售销售额的商品的累计占比>A的阈值,那就划分为A类,这样就可以保证始终有A类。
ABC分类4 =
var maxsales = MAXX( ALL('销售表'), [销售] )
var cur = [累计占比4]
return
SWITCH(
TRUE(),
cur<=[A范围] || [销售]=maxsales,"A",
cur<=[B范围], "B",
"C"
)
总结
其实,这里在算累计值的时候进行了取巧,比如事实数据是已经聚合好的数据,实际计算中事实表可能几百上千万行数据,这时在计算时就要先聚合出来一张表变量表,然后再进行相应的计算,这样可以减少迭代,从而加快计算速度。关于ABC分类更详细的算法可以查看SQLBI的文章ABC classification – DAX Patterns[1]
生活中,我们总是希望可以花20%的时间就获取80%的效果,比如什么30分钟读完一本书,一周掌握一门语言,对于天才,可能确实可以这样,对于普通人还是要花足够的投入的,也就是所谓10000小时理论。
引用链接
[1] ABC classification – DAX Patterns: https://www.daxpatterns.com/abc-classification/
本篇文章来源于微信公众号: PowerBI木小桼